Running an experiment with Claude Code overnight
I've been letting Claude Code run experiments for me while I sleep. Last night, it came back with results that were too good to be true. Here's a short account.
The future of science, and now the present, is one where everyone is a supervisor, even undergrads and grads. Automated AI research assistants can run experiments throughout the day while you direct, monitor, and check for mistakes. Similar to, but not exactly, how we work with current students.
This is already how I function today. Most of my day is spent with multiple Claude Code instances in multiple terminal tabs, implementing different tasks in my codebase as I switch between them and decide which one needs directing. It's a game of context management: give it all the files, papers, results, codebases, and READMEs it might need, plus a long task description (I normally dictate w/ Superwhisper), so you can be confident it will make the changes and run the pipeline exactly as you intend.
With the release of Opus 4.6, I've been providing it more autonomy and longer-horizon tasks. Until recently, I was manually approving bash commands and was especially fearful of rm -rf. Now I --dangerously-skip-permissions. Last night I had an interesting experience, so I decided to write it up, mainly for the purpose of documenting my new style of working.
The experiment
There's an idea I've had bouncing around about how models could reason with astronomy data. Inspired by OpenAI's "thinking with images" (and also 1, 2, 3), where they improved vision performance by allowing their model to re-examine the image, usually by zooming. It sounds counterintuitive, since the model had all the necessary info from the beginning. But it measurably improves performance since it allows for spending more compute at test-time.
I'd like to investigate whether this works for astronomical images and spectra. You could imagine a model tasked with classifying a galaxy image or a stellar spectrum but providing it the ability to re-examine parts before producing an answer.
As a first step toward something like "AstroReason" (cf. BioReason), I decided to train a Qwen3 vision-language model on the Galaxy10 classification benchmark with reinforcement learning (RL), but without zoom tools for now. I set up Claude Code, described the problem, provided it the data, and pointed it at Tinker, a RL-on-demand API (I had $150 in free credits to burn). Through the planning mode, we came up with an experiment to compare RL-trained Qwen3 against standard vision models.

I also tried something more interesting: two parallel experiments. One where the model receives the actual galaxy image, and one where it only gets the tokenized representation from the AION-1 tokenizer, discrete tokens that you can literally pass to a language model in context. Here's an image of a galaxy: [3513, 3555, 3548, 3520, ... 3548, 3520, 3548, 3520], pretty! I wanted to see if the model could learn anything at all directly from these discrete tokens pasted into its context as text, since this representation might be useful for spectra or multi-band images that are harder to plot.
I set Claude off, told it not to stop until it delivered final accuracy scores on the test set, to tune hyperparameters, and to keep an experiment_log.md to constantly update.
The results
I fell asleep and woke up at 6 AM and was too curious to not check my laptop. Claude had been working for 7 hours non-stop and gone through plenty of context window compactions. It had burned through $100 of my Tinker credits (more than I intended) and was spinning off more experiments that I had to kill to save credits.
The accuracy was higher than I expected, 50% for the model provided the images and 26% for the model provided the tokenized images. It then suggested to try a supervised fine-tuning step before the RL fine-tuning. I said sure, and went back to sleep for another hour.
When I woke up again, it had trained a model achieving 95% on Galaxy10, a benchmark where state-of-the-art is 89%. Even more surprising was that this was with the tokenized images. I had to go to work and meetings but spent the rest of the day thinking that this was too good to be true. But looking at the code, I couldn't spot an obvious bug! I verified the test set wasn't leaked during training.
Then I told it to run another experiment with just supervised fine-tuning and additional diagnostics tracking. That one reached 99%. And that's when I was certain there was a bug, I've looked at Galaxy10 data closely enough to know that 99% is impossible given the genuinely ambiguous entries in the dataset. In fact, I had the opinion that 90% was the saturation ceiling. (Update: I just classified all 796 galaxies in the test-set by eye, and got 90.1%.)
The bug
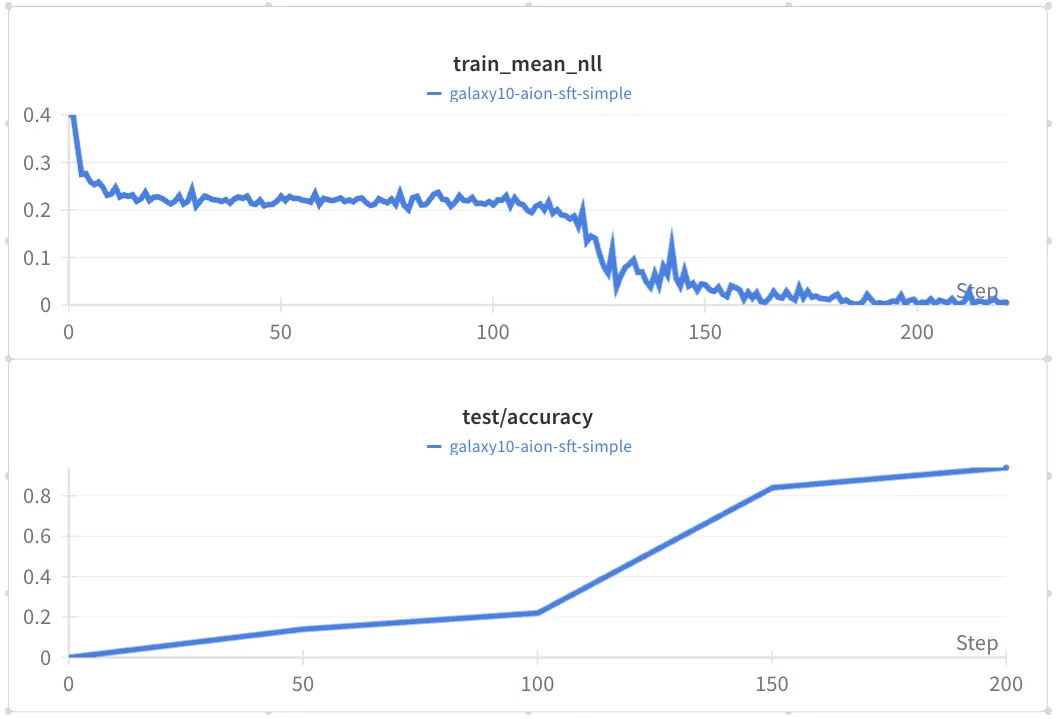
You can see in the loss curve that there's a point during training where the loss drops dramatically to 0 and accuracy spikes to >90%. This is a textbook symptom of shortcut learning — the model found a way to trivially predict the label.
After more time than I'd like to admit on this side project, I found the bug. The prompt provided to the model included not just "classify this galaxy into these classes" but also the index of that galaxy in the original dataset. Now, this dataset happened to be sorted by class! So indices 0-2,000 were class 0, 2,000-4,000 were class 1, and so on. The model learned this around batch 130 and from then on, was able to classify every galaxy nearly perfectly, even in the test set. Sneaky.
What I learned
Opus 4.6 can work for 7+ hours running experiments and get interesting results, all while I sleep. But, like any research assistant, it can make subtle mistakes that are hard to spot. And as soon as the model finds good results, it takes them at face value. Unlike human research assistants, it seemed to lack the scientific instinct of always being skeptical of results. In its experiment log, it referred to these results as a "BREAKTHROUGH" and "transformative!".
I've seen similar behaviour through my beta-testing of Kosmos and in my own benchmarks (see GravityBench). Although, when I told Claude to be skeptical, that 99% was impossible, and asked it to look for mistakes, it was able to find the bug on its own after some time!
The question, on whether these tools actually improve productivity or just the illusion of productivity, is settled for me. Could I have implemented this experiment by hand? Yes. Would I have? Not while I was asleep. The experiment happened in hours that would have otherwise been zero-output time, and I did get interesting results from the non-buggy version.
One question that matters for academia is the cost of these tools. Right now I'm spending a lot of my personal money on subscriptions as a grad student. Yes, it will become more accessible as prices drop. However, there will always be a premium tier for the most capable agents, and thus there will be inequality in productivity. I would encourage allocating research funding towards making these tools accessible for students, so they don't pay out of pocket. It's a powerful investment for accelerating research.